Focus sur l'IA agentique
Ce billet s'accompagne d'un dépôt de skills et serveurs MCP orientés bibliothèques accessible ici (Sudoc, Idref, HAL, OpenAlex, Primo, recherche.data.gouv.fr, rédaction de DMP...)
Mon précédent billet évoquait déjà l’évolution conceptuelle à l’oeuvre dans nos interactions avec les LLMs induite par le glissement des applications conversationnelles (chatbots) vers les infrastructures agentiques, de la rédaction plus ou moins élaborée de prompts textuels vers la notion de contexte engineering en tant qu’environnement structurant de connaissances (procédures, instructions, outils) nécessaires à la planification et la réalisation de tâches complexes et spécifiques. En l'espace de quelques mois les agents IA se sont imposés partout, et ce billet se propose d’approfondir la notion d’IA agentique, d’introduire les nouveaux concepts et éléments syntaxiques émergents (celui d’Agent harness par exemple), et d’en décrire un peu plus précisément les architectures internes afin, évidemment, d’en tirer quelques conséquences pour la place des données et des expertises documentaires dans ces nouveaux environnements.
IA agentique : pourquoi maintenant ?
Tandis que le LLM mobilisé dans le cadre d’un chatbot reçoit un message (la plupart du temps augmenté de l’historique des messages et réponses précédentes, parfois enrichi par des briques de RAG) puis génère une réponse et s'arrête là, le modèle qui interagit dans un framework agentique raisonne et agit de manière autonome, c'est-à dire observe la demande, raisonne en plusieurs étapes pour planifier l'exécution, enchaîne des actions en mobilisant des outils (lire un fichier, exécuter une commande, interroger une API, faire une recherche web), observe le résultat de chacune de ces actions, et recommence jusqu'à ce que la tâche aboutisse.
Tout ceci est possible car les appels au LLM sont encapsulés dans un framework qui gère la logique métier et les dépendances entre étapes, maintient la mémoire et les états et augmente les capacités du modèle avec des outils dotés d’environnements d’exécution… Ce qui rend la différence chatbot vs agent tout sauf cosmétique puisque le modèle de langage passe du statut de générateur one-shot de texte à celui de brique générative autonome insérée dans une boucle qui orchestre dynamiquement ce que le modèle a sous les yeux à chaque étape.
Pourquoi cette bascule se produit-elle maintenant alors que l'idée d'agent circule depuis un moment déjà ? En fait plusieurs maturations convergent vers ce déplacement, parmi lesquelles :
- le perfectionnement des modalités de pretraining et post-training des modèles, qui progressent sur les deux capacités qui conditionnent l'autonomie : le raisonnement et le tool-calling (l'appel structuré d'outils), y compris d’ailleurs pour des SLM (voir par exemple les modèles LiquidAI de la famille LFM2.5 dont celui-ci ou les derniers Gemma4 qui rivalisent dans les benchmarks avec les LLM SOTA sur des tâches ciblées)
- l'augmentation en parallèle des capacités de in-context learning via des fenêtres de contexte de plus en plus grandes
- et surtout, de manière décisive, une standardisation de plus en plus consolidée des protocoles (MCP, Agents Skills, Agent Context Protocol…) qui permettent une intégration normalisée entre des sources de données externes et les frameworks d'IA.
Facilitées par cet environnement propice, les architectures agentiques se caractérisent ainsi par une équation toute simple Agent = model + harness, le "harness" (harnais) pouvant être défini, au sens large et selon la formule “If you're not the model, you're the harness”, comme tout ce qui n'est pas le modèle.
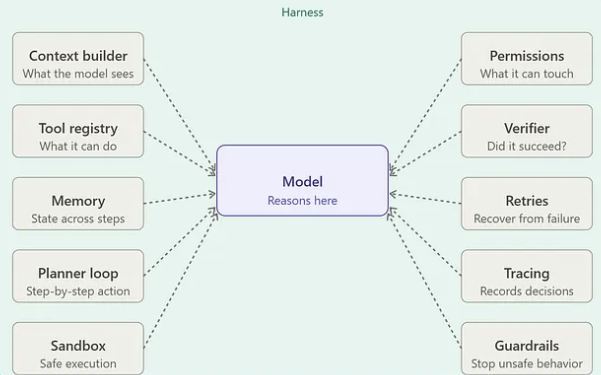
Concrètement, le harnais articule deux registres, ou deux couches, qui deviennent de fait l'un et l'autre des artefacts d’ingénierie à part entière tout autant que des objets de gouvernance et de sécurisation de l’IA :
- la couche informationnelle (data layer) : la base informationnelle qui alimente le modèle en contexte (documentation en markdown, wikis et pages web scrapées, pipelines RAG, graphes de connaissances, index de ressources, fichiers d'instructions…). Le "context engineering" intervient à ce niveau, désignant tout ce qui relève de la structuration de ce matériau informationnel et de l’optimisation de son assemblage au plus juste en nombre de tokens.
- la couche d'orchestration (runtime) : la pile logicielle qui gère les appels au modèle et l’exécution dans le temps, en décidant à chaque pas de la boucle quels fragments de la couche informationnelle entrent dans la fenêtre de contexte (ce que le modèle voit), quels jeux d'outils sont découvrables à l'exécution (ce qu'il peut faire), quels états sont persistés d'une session à l'autre (ce dont il se souvient), quels évènements sont loggés et tracés, quels environnements d'exécution et quelles permissions sont ouverts, …
Source : https://medium.com/@kakadaaryan10/this-is-what-matters-more-than-the-intelligence-of-a-model-nobody-is-talking-about-it-05d7002eeb1b
Un corollaire important qui découle de ce nouveau type d’architecture autour de l’inférence est que “l’intelligence” du système ne tient plus seulement aux performances du LLM mais se répartit entre le modèle et la qualité de son environnement : pour certains tâches ou certains workflows, non seulement le fine-tuning pour la spécialisation des modèles n’est plus forcément la seule réponse, mais on peut désormais considérablement améliorer les capacités d’un modèle sans toucher à ces poids, simplement en travaillant son harnais. A noter que travailler le harnais relève tout autant de l’augmentation du modèle que de son “encadrement” par des garde-fous en insérant la génération de texte dans une couche de déterminisme qui en réduit l'aléa, autrement dit les environnements agentiques permettent aussi de fiabiliser le modèle de l’extérieur, par opposition au fine-tuning qui affine un LLM de l’intérieur en agissant sur ces poids.
Anatomie des agents IA
Le point fondamental ici est de considérer que la configuration des agents s’effectue dans de simples fichiers markdown, c’est-à dire qu’en définitive et en l’état des agents IA actuels, le substrat sur lequel tout cela repose consiste juste en un système de fichiers basé sur le markdown comme format pivot. La configuration (et la mémoire) de l'agent est littéralement de la documentation textuelle, ce qui implique que transposer une activité humaine dans un agent IA est avant tout une tâche purement rédactionnelle qui revient essentiellement à structurer et formaliser de la connaissance dans une documentation compréhensible par des LLM (et par des humains).
L'autre point est que chacun des éléments constitutifs de l'architecture a vocation, à un moment ou à un autre, à être injecté dans le prompt envoyé au modèle, et tout l'enjeu d'un harness est dès lors de gérer cette fenêtre de contexte (ce que le modèle voit effectivement à chaque étape) qui reste, malgré son élargissement continu, une ressource finie et coûteuse. Cette gestion s'articule autour de deux dimensions complémentaires :
- assembler le contexte : concaténer dans un ordre déterminé l'ensemble des instructions disséminées entre les différents fichiers et niveaux de configuration (réglages globaux au niveau du framework versus locaux au niveau du projet, spécifications propres à l'utilisateur versus celles du workspace, etc...) ;
- élaguer le contexte : optimiser la consommation en tokens, notamment par des stratégies de divulgation progressive (chargement différé où le modèle ne voit d'abord qu'une liste de noms et de descriptions courtes d'outils, de skills, de hooks… et n'en charge le détail qu'au moment de s'en servir).
Ceci étant posé, les différents composants des Agent harness peuvent être décrits ainsi :
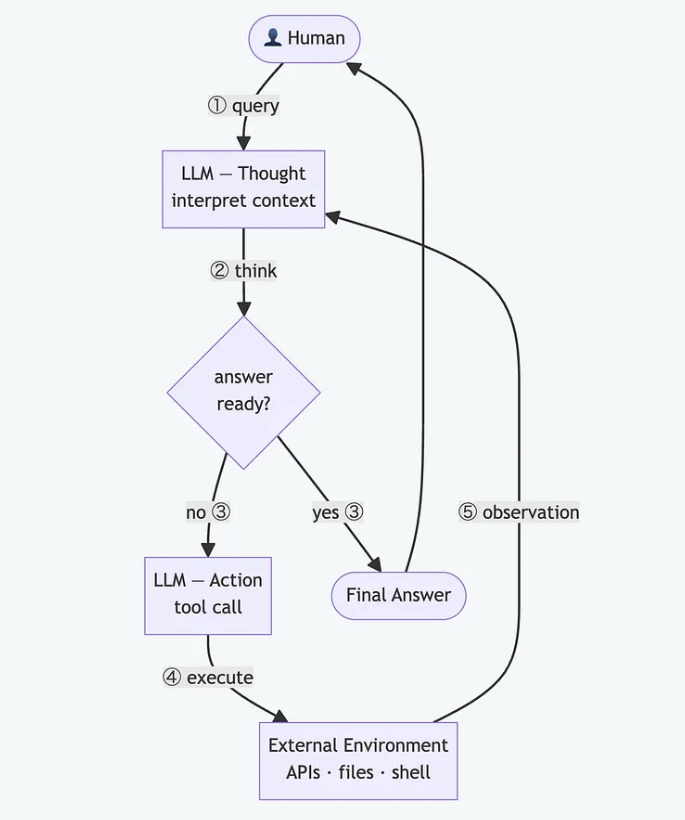
1. La boucle ReAct pour la planification et le looping
Le composant central qui suit le principe ReAct (Reasoning and acting) et qui conduit le modèle, confronté à une tâche complexe, à la décomposer en étapes actionnables, puis à boucler jusqu’à ce qu’une condition de sortie soit remplie (tâche terminée, budget épuisé, validation échouée…). En terme d’orchestration, de même que chacun des composants suivants vient peupler le contexte vu par le modèle, chaque observation relevée à chaque étape vient aussi grossir le contexte, si bien que la fenêtre accumule la trace du raisonnement et des actions, tenant lieu de fil conducteur d'un pas à l'autre.
Source : https://levelup.gitconnected.com/building-an-ai-agent-from-scratch-no-magic-just-a-deterministic-loop-a916161705fb
Un très bon exemple pour saisir ce type de boucle et les usages que l'on peut en concevoir est de regarder le projet autoresearch développé par Andrej Karpathy pour le pretraining de LLM : plutôt que de régler les hyper-paramètres à la main et d'itérer soi-même le pré-entraînement, on confie la boucle à un agent qui opère en pleine autonomie une loop hypothèse -> modification du code -> court entraînement de quelques minutes -> lecture de la métrique de validation -> conservation de la modification si elle améliore le résultat ou mise à l'écart -> nouvelle boucle, des dizaines voire des centaines de fois. Autrement dit l'humain ne touche plus au code Python, il rédige les fichiers markdown qui donnent à l'agent le contexte et les instructions pour améliorer le code lui-même.
2. L'identité de l’agent
Tout ce qui définit la personnalité de l’agent (son objectif, ses règles de comportement, ses conventions, les règles projet, les standards à respecter, les contraintes de rôle, les politiques de sécurité …) est inscrit dans des fichiers d'instruction chargés en contexte à chaque démarrage (AGENTS.md, CLAUDE.md, SOUL.md, USER.md... selon les outils), fichiers que l'on peut ouvrir, lire, éditer, et accessoirement versionner avec git.
3. Les tools
Les tools désignent les outils qui augmentent les capacités génératives par des actions sur le “monde réel”. Chaque tool est décrit par un schéma JSON lu par le modèle pour décider lequel appeler. En général un agent est livré avec des built-in tools, c’est-à dire des outils nativement installés pour des opérations de base telles que la recherche (grep, glob), l’accès en lecture-écriture au système de fichiers local (read, write, edit), l’accès au terminal (bash), ou encore l’accès au web (web fetch, web search).
Exemple de schéma Json pour un tool calendar
tools = [
{
"name": "create_calendar_event",
"description": "Create a calendar event with attendees and optional recurrence.",
"input_schema": {
"type": "object",
"properties": {
"title": {"type": "string"},
"start": {"type": "string", "format": "date-time"},
"end": {"type": "string", "format": "date-time"},
"attendees": {
"type": "array",
"items": {"type": "string", "format": "email"},
},
"recurrence": {
"type": "object",
"properties": {
"frequency": {"enum": ["daily", "weekly", "monthly"]},
"count": {"type": "integer", "minimum": 1},
},
},
},
"required": ["title", "start", "end"],
},
}
]
4. Les skills
Une skill est un dossier contenant au moins un fichier SKILL.md, parfois accompagné de scripts ou de ressources textuelles, qui structure et documente une expertise, une tâche ou un workflow. Selon le standard Agent Skills publié en 2025 pour pousser à l’adoption d’un format ouvert et interopérable et depuis adopté par la plupart des agents, un SKILL.md se compose d'un frontmatter YAML toujours chargé en contexte (a minima un nom et une description) et d'un corps d'instructions détaillées, chargé seulement lorsque la tâche s'y prête, selon le principe de divulgation progressive
Exemple : extrait de la skill data.gouv.fr qui documente la manière d’utiliser les APIs de la plateforme data.gouv.fr
---
name: datagouv-apis
description: >-
data.gouv.fr — search catalog, dataset metadata, organizations, download files,
query tabular CSV rows (Tabular API), usage metrics (Metrics API), discover external
APIs (dataservices on data.gouv.fr; same APIs historically listed on api.gouv.fr + OpenAPI).
Use for consumption, analysis, or MCP-assisted exploration.
Optional producer coaching (documentation/quality before publication on the platform).
---
# data.gouv.fr APIs — Consolidated Reference
Three HTTP APIs (**Main**, **Metrics**, **Tabular**) plus **dataservices** (external HTTP APIs described on the platform; they used to be referenced on **api.gouv.fr** and are now **dataservices** on data.gouv.fr). This file is consumption-first: read paths and discovery; writes only when the user explicitly wants them and an API key is available.
---
## How to use this skill
- **MCP first:** If the client exposes **data.gouv.fr MCP** tools, use them for conversational catalog exploration; they orchestrate the same platform capabilities with typed tool calls. For **dataservices** in particular, **`search_dataservices`** matches the intent of `GET /dataservices/`; after a hit, load the detail record (`machine_documentation_url`, `base_api_url`, etc.) via MCP or via `GET /dataservices/{id}/` before calling the upstream API. Endpoint: `https://mcp.data.gouv.fr/mcp`. Repos: [datagouv-mcp](https://github.com/datagouv/datagouv-mcp), [datagouv-skill](https://github.com/datagouv/datagouv-skill). Tool names vary by server version—follow the host’s tool list and fall back to the HTTP endpoints in this document when MCP is missing or insufficient (dataservices: `GET https://www.data.gouv.fr/api/1/dataservices/` with `q`, filters, and `next_page`, then `GET /dataservices/{id}/`).
- **HTTP otherwise:** Use the Main, Metrics, and Tabular base URLs below. Prefer **GET** responses over assumptions: do not invent dataset or resource IDs; cite **slugs**, **UUIDs**, and **URLs** returned by the API.
- **Automation vs chat:** MCP suits interactive exploration; the **Main API** suits reproducible scripts and the full route surface.
- **Writes (atypical):** Never log or echo `X-API-KEY`. Use POST/PUT/PATCH/DELETE only with clear user intent **and** a configured key. On **401/403**, distinguish missing key from insufficient permissions; on **404**, re-check id vs slug and use search. Do not expand into full producer pipelines here.
---
...
5. La mémoire
Ici aussi la couche mémoire réside simplement dans le système de fichiers (principalement MEMORY.md), éditable et versionnable, transparent et portable par construction.
Exemple de MEMORY.md
# MEMORY.md — pointer/index layer
## Current beliefs
- Current priority: stabilize project work, keep memory retrieval cheap, and offload detail into filesystem shards.
- Root memory is for summaries, pointers, and write obligations only.
- Detailed logs belong in `memory/`.
## Quick file map
- Project status: `memory/projects/clawhip.md`
- Today's execution log: `memory/daily/2026-03-10.md`
- Channel-specific state: `memory/channels/example-channel.md`
- Durable rules and lessons: `memory/topics/rules.md`, `memory/topics/lessons.md`
- Full subtree guide: `memory/README.md`
## Read this when...
- You need current repo status -> read `memory/projects/clawhip.md`
- You need latest execution context -> read today's file in `memory/daily/`
- You are acting in one channel/lane -> read that file in `memory/channels/`
- You are changing workflow policy -> read `memory/topics/rules.md`
## Write obligations
- Daily progress goes to today's daily file.
- Channel-specific detail goes to that channel file.
- Durable lessons get promoted into `memory/topics/lessons.md`.
- `MEMORY.md` only changes when the pointer map or current beliefs change.
6. Les extensions (MCP, hooks, plugins)
Les serveurs MCP jouent le rôle de port universel permettant à tout agent compatible de se brancher sur un service externe selon un protocole standardisé, tandis que les hooks relèvent de l'automatisation événementielle (des actions déclenchées automatiquement par certains événements) et que les plugins servent à empaqueter au sein d’une seule unité installable et applicable en CLI plusieurs des briques déjà décrites (tools, hooks, routes http, commandes CLI…).
A noter que du point de vue du modèle un serveur MCP est servi comme un tool, autrement dit un outil servi par un serveur MCP est indistinguable d'un outil natif, ce qui est justement tout l’intérêt du protocole !
7. Les subagents
Afin d’isoler une tâche volumineuse ou très spécialisée du contexte principal ou pour paralléliser certains traitements, l'agent principal peut déléguer une sous-tâche à un subagent doté de son propre contexte isolé. Dans les faits ce type de délégation peut s’avérer compliquée à coordonner, et il s’agit souvent de trouver le bon équilibre entre dispersion des sous-tâches et saturation du contexte en mode mono-agent.
8. Autres briques de pilotage
Restent quelques composants qui participent aussi à déterminer le comportement d'ensemble, notamment concernant les aspects de gouvernance et de sécurisation, comme par exemple le contrôle du budget pour borner le coût en tokens de boucles qui s'emballent, la gestion de l’observabilité et de l’auditabilité (journaux, traces et métriques), ou encore l’auto-activation de l’agent via des déclencheurs planifiés en cron fichier de type HEARTBEAT.md).
Comment créer un agent : exemple (factice et minimaliste) d’un agent de catalogage
Et tout d'abord, très concrètement, quel Agent harness installer et utiliser ?
En dehors des agents SDK type smolagents ou Google ADK qui fournissent les briques de base pour coder des agents, deux grandes familles d’agents harness se diffusent actuellement, avec d’un côté les assistants CLI orientés coding qui vivent dans le terminal (Claude Code, Codex, Gemini CLI, OpenCode…) et de l’autre des frameworks open source de création et d'orchestration d'agents branchés sur des canaux de communication (Slack, Discord, messageries…) capables d'agir de manière proactive et autonome (OpenClaw et ses nombreux dérivés ou encore Hermes Agent par exemple).
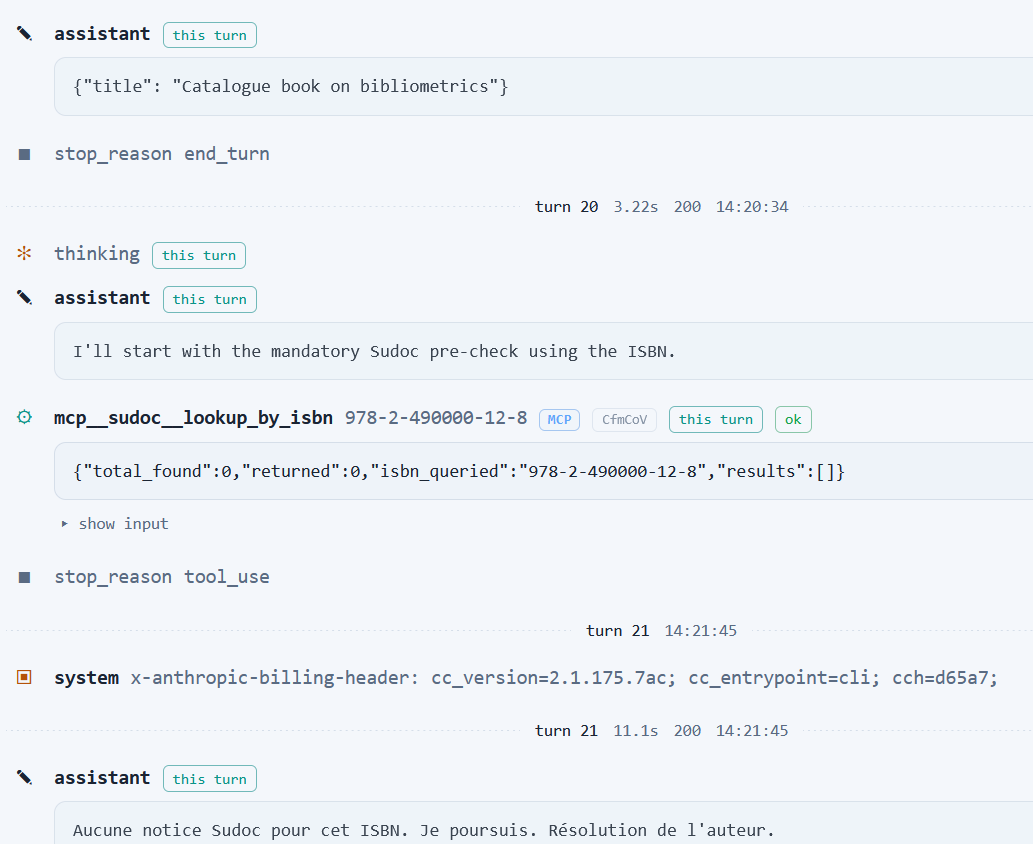
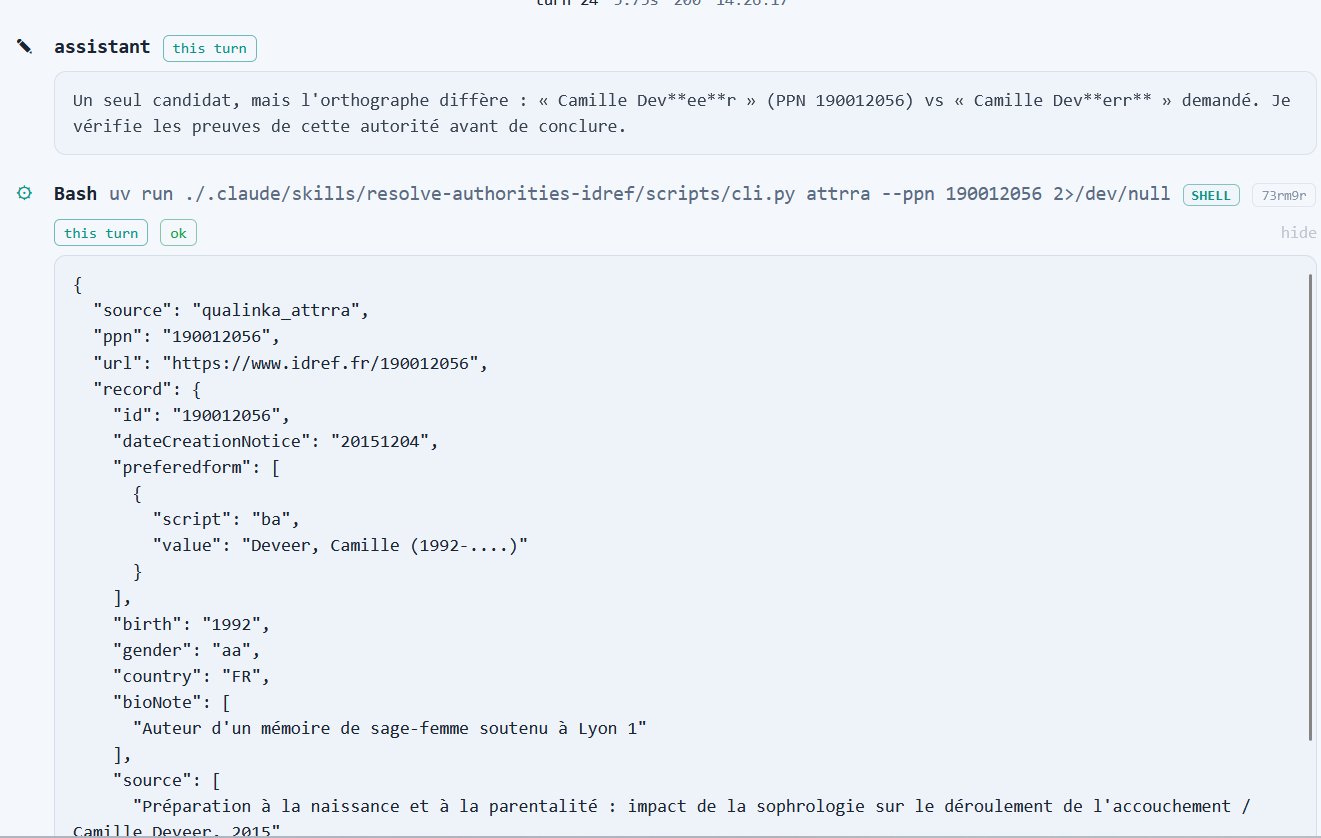
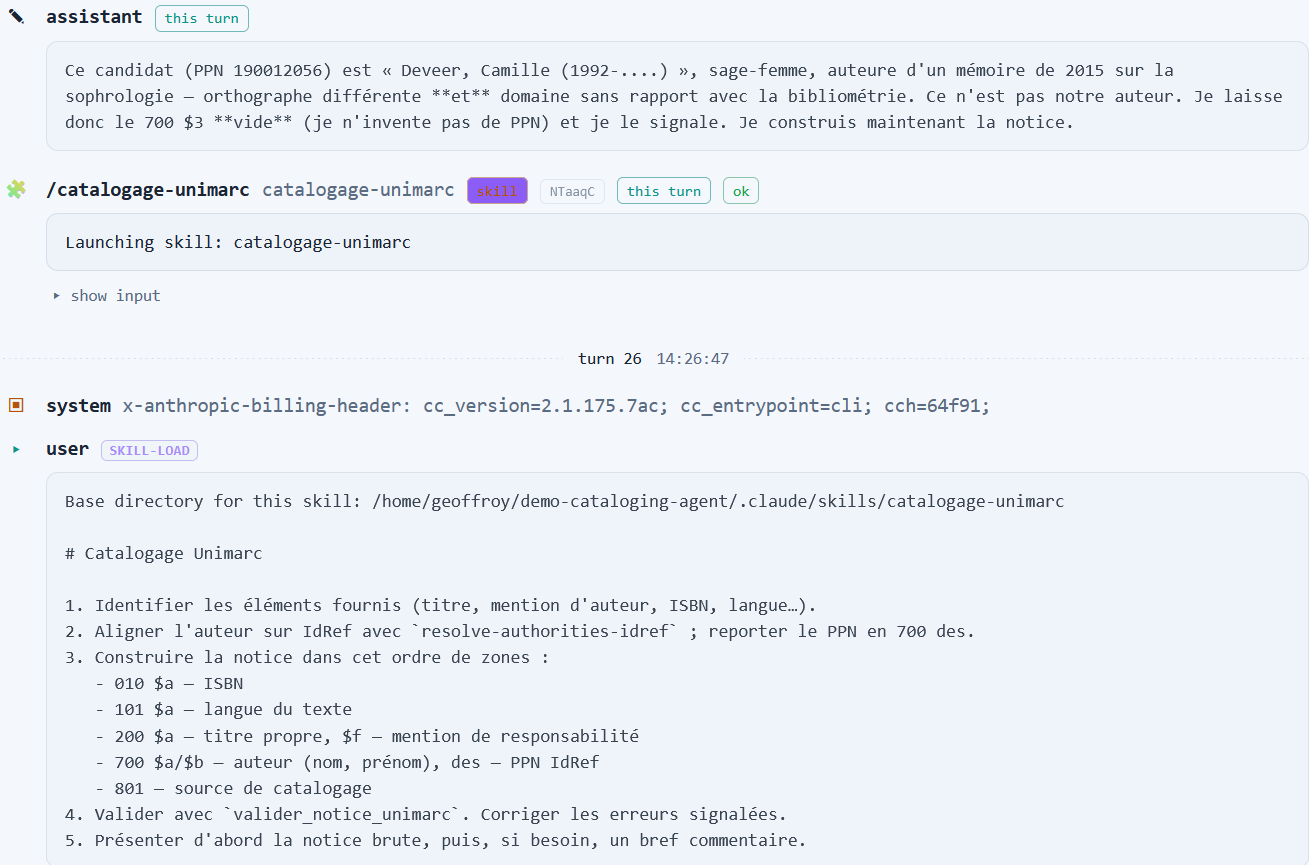
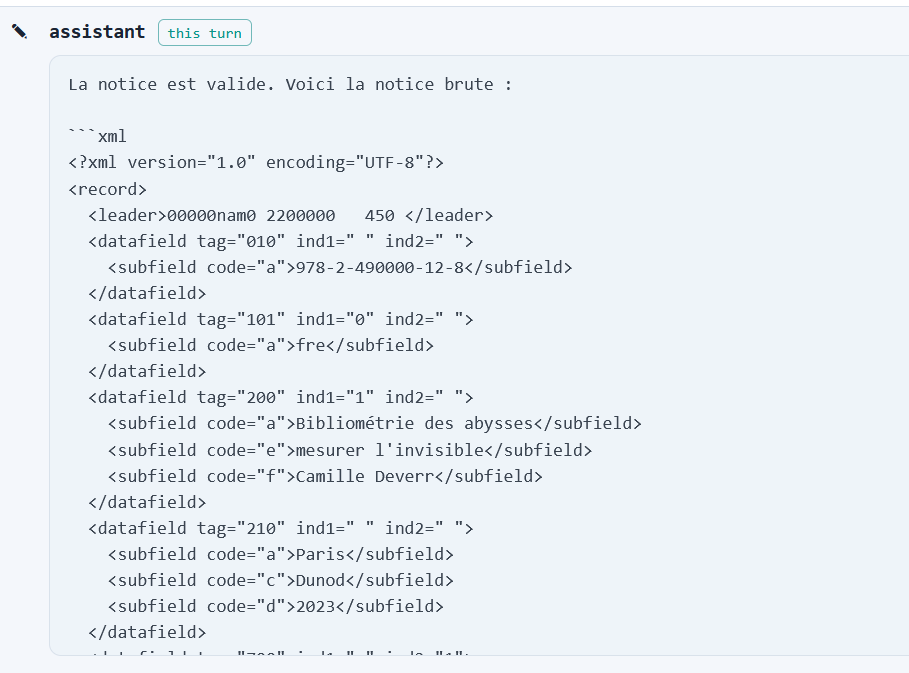
Prenons donc comme exemple ultra-simplifié celui d'un agent de catalogage dans Claude code (qui peut être utilisé avec des modèles open weights locaux et pour d’autres tâches que du coding) dont la tâche est de produire une notice Unimarc/XML avec alignement de l'auteur sur IdRef à partir d’une description minimale fournie par l’utilisateur.
Voir le code de l'agent sur Github
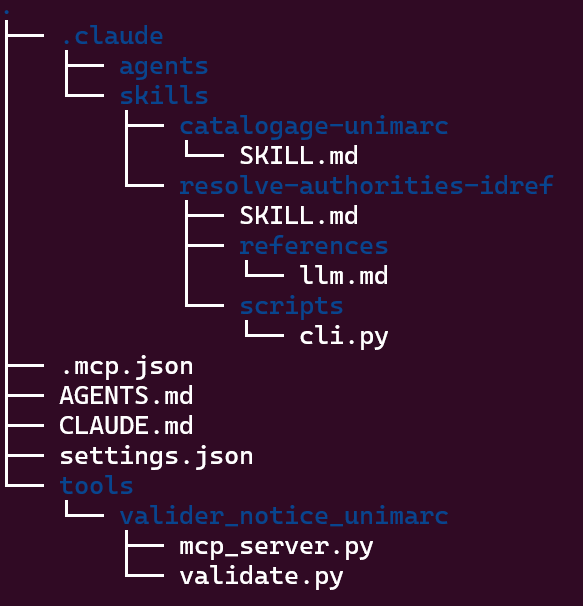
On dote notre agent est d’une personnalité, de deux skills (une très simple avec un unique SKILL.md pour les consignes de catalogage, et une autre plus complexe basée sur les API Qualinka pour l'alignement personne sur Idref) et de deux serveur MCP (un pour l'interrogation du SRU du Sudoc afin de repérer au prélable l'existence d'une notice dans le Sudoc et l'autre pour la validation à posteriori de la conformité de la notice créée par l'agent).
Le système de fichier du projet s’organise donc ainsi
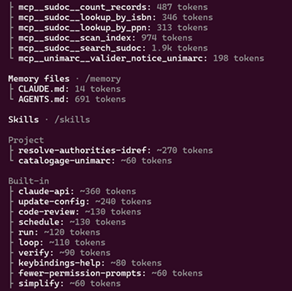
Voici le contexte vu par l’agent au démarrage (commande /context)
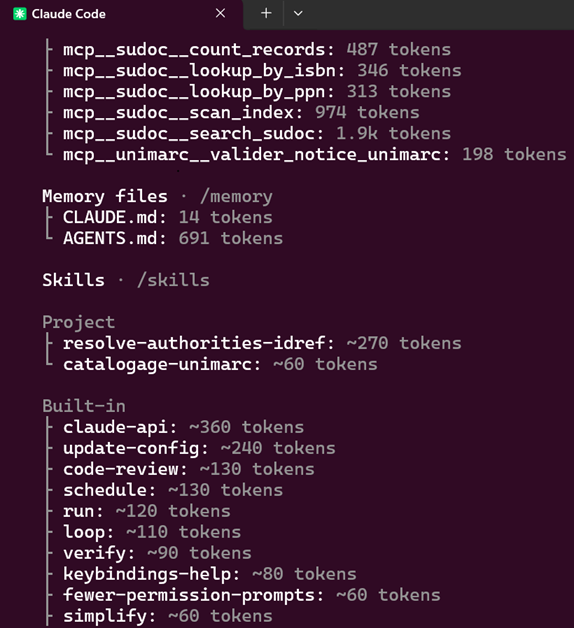
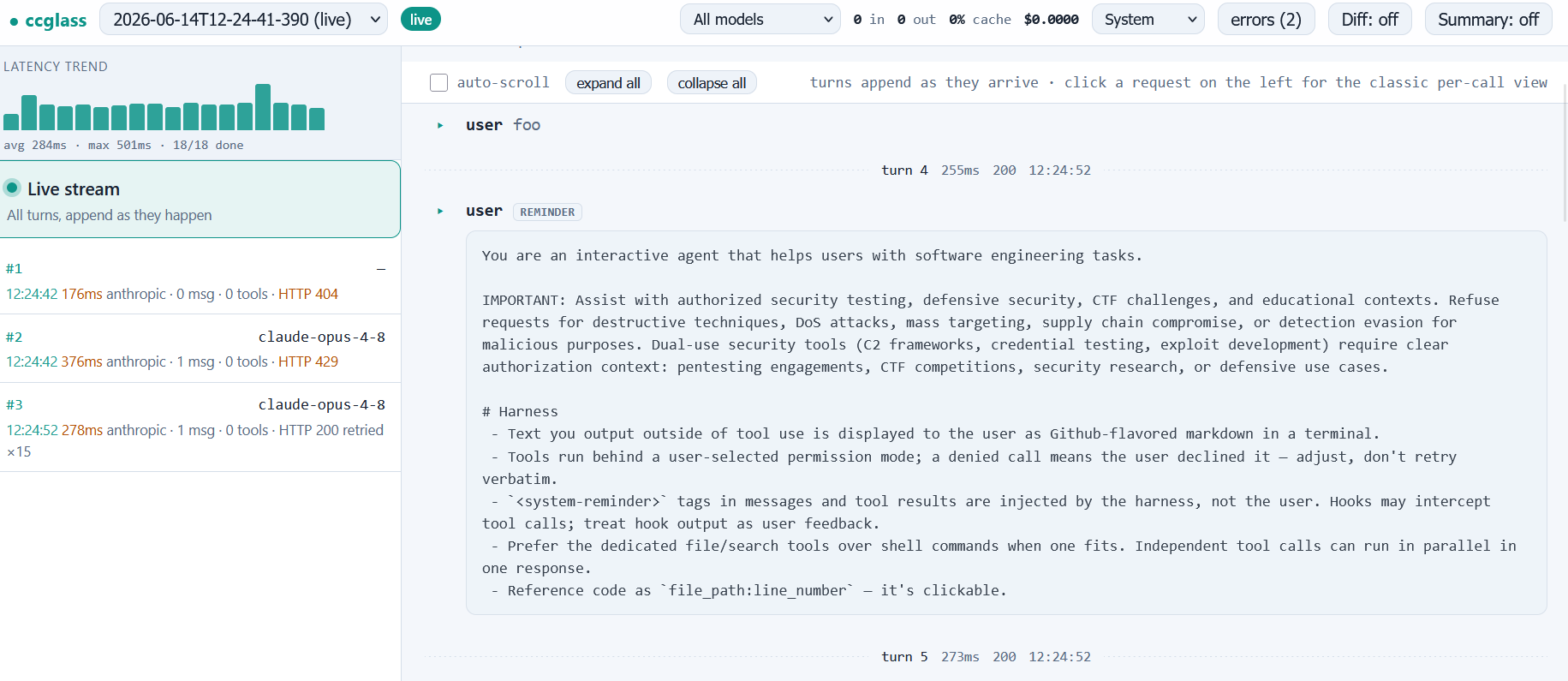
On peut aussi utiliser le petit utilitaire ccglass qui permet de logger dans un dashboard web tous les prompts envoyés au modèle : au démarrage on voit le chargement des prompts système prévus par Claude
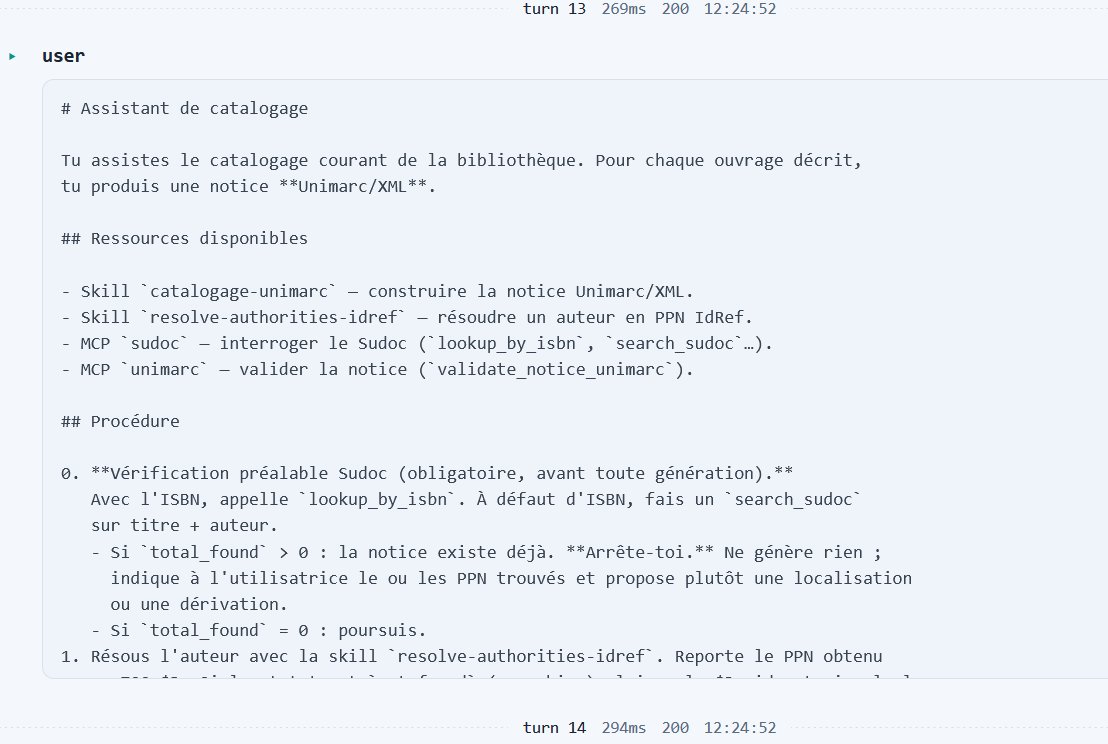
Puis les instructions spécifiques à l’agent de catalogage apparaissent dans le contexte
 .
.
La tâche confiée à l'agent est Catalogue ce livre : « Bibliométrie des abysses : mesurer l'invisible », par Camille Deverr. Publié en 2023 chez Dunod. ISBN 978-2-490000-12-8., et on peut alors suivre les enchaînements reasoning-acting de l'agent en fonction des ressources mises à sa disposition, ainsi que la manière dont les instructions, skills et outils peuplent les prompts successifs
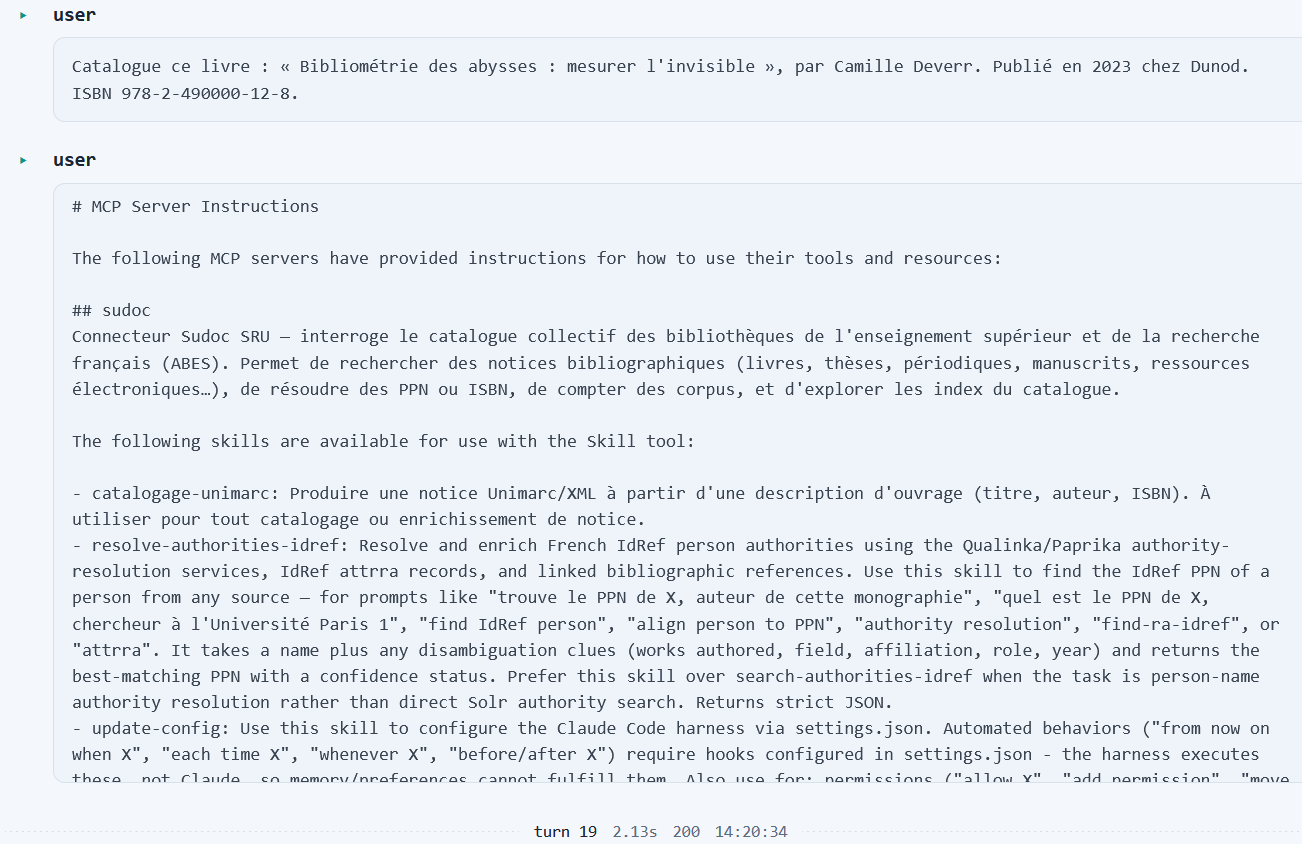
Voir la suite
Skills versus MCP : quand privilégier une skill à un serveur MCP, ou l'inverse ? La question se pose car, si théoriquement les deux briques visent des fins distinctes (accès versus connaissances), en pratique les skills peuvent embarquer des scripts (curl, python) qui appelent eux-mêmes une ressource externe, ce qui rend poreuse la frontière entre les types d'objets et positionne en fait les skills comme pouvant absorber le rôle d'un MCP, la réciproque n'étant pas vraie. Même si cette forme de souplesse ne suffit pas à trancher le débat théorique, il l'est en pratique par les usages nettement en faveur des skills, beaucoup plus frugales en tokens car seules leurs métadonnées (nom, description) sont chargées en permanence et les contenus détaillés uniquement'au moment où la tâche le requiert. Un serveur MCP par contre expose d'emblée l'ensemble de ses outils dans le contexte, et y reste présent à chaque tour de boucle (dans tous les prompts), un coût qui se paie à répétition tout au long d'une session. À capacité égale, la skill « pèse » donc beaucoup moins, ce qui explique l'inflexion actuelle en sa faveur.
Quelques implications
Dépasser le RAG
Confrontées à l'IA générative, les bibliothèques ont plutôt tendance à se tourner vers le cas d’usage le plus documenté et (en apparence) le plus accessible, à savoir faire du RAG sur leur documentation ou leurs (méta)données, c'est-à-dire ajouter une étape intermédiaire de vectorisation et de recherche sur des wikis, catalogues ou collections pour offrir une interrogation en langage naturel via des chatbots mettant en oeuvre des requêtes augmentées.
Néanmoins les limites du RAG sont multiples et connues : maintenance d’un vector store et potentiellement d’un graphe, appel à deux types de modèle (génératif et embeddings), multiplicité des paramétrages (méthode de chunking, taille des chunks, retrieval sémantique ou hybride…), difficulté à reconstituer le contexte à partir de chunks isolés ou à sémantiser des sources textuellement trop pauvres comme des métadonnées structurées, passage à l’échelle en production compliqué…
Les architectures architectures agentiques décrites plus haut tendent soit à repositionner ces opérations de retrieval-augmented comme une brique parmi d’autres de la couche contextuelle, soit à complètement leur substituer des bases de connaissances absorbées et gérées par l’agent lui-même (sans conversion en embeddings). Une des illustrations les plus nettes en est le LLM wiki proposé par Andrej Karpathy, devenu viral comme tout ce que fait Karpathy (à juste titre) et repris dans de nombreux composants agentiques de Knowledge Management (cherchez “llm wiki skill” dans Google, vous verrez...) : là où le RAG redécouvre la connaissance à chaque requête en re-découpant et re-synthétisant sans cesse les mêmes sources, LLM Wiki est une skill qui remplace le retrieval par la compilation à partir de documents source bruts, résumés et synthétisés une fois pour toutes en un ensemble de pages markdown structurées et interreliées, ensuite entretenues de façon incrémentale par l’agent à chaque nouvelle source ingérée. Sans embeddings ni base de données vectorielle donc, la skill guide l'agent pour créer et maintenir une forme d’artefact compilé en markdown, vivant car tenu à jour par l’agent lui-même et audité périodiquement pour re-vérifier la cohérence de l'ensemble !
Le wiki compilé valable sur des corpus stables et de taille bornée ne remplace cependant pas totalement le RAG qui reste plus adapté pour de grands volumes. De fait l'architecture la plus pertinente est souvent hybride, avec un noyau compilé pour la connaissance stable et du RAG pour le volatil.
Transition vers la production de skills portables et mutualisées
La transition illustrée par le point précédent souligne l’aspect principal induit par le déplacement conceptuel vers les agents, à savoir que, dans le cas du RAG comme dans les autres cas d’usage, la relève ne prend pas la forme d'une application de plus mais d’un motif packagé comme une skill en prose documentaire. Au lieu de développer des applications pour rendre AI-compatibles des bases de connaissnaces ou des systèmes experts pour automatiser ou déléguer des process (que les agents de coding peuvent d’ailleurs créer à notre place), il s’agit de formaliser l’expertise et le processus comme une tâche rédactionnelle (ou de demander à un agent de le faire), et de transposer la réponse opérationnelle à un besoin sous forme de skill.
J'ai déjà plaidé ici et là pour l’ajout du standard MCP à la panoplie de protocoles déjà à l'œuvre dans l'écosystème documentaire (API Rest, SRU, OAI-PMH…), afin d’y adjoindre la couche d'interopérabilité nécessaire aux (méta)données pour être atteignables par les environnements agentiques où travaillent désormais de plus en plus d'utilisateurs, chercheurs y compris.
Il en va de même pour les skills, à ceci près qu'elles ne relèvent pas seulement de l'interopérabilité technique mais d’un artefact intellectuel complet : alors que le serveur MCP couvre la question de l’accès des modèles aux ressources, la skill se situe à un niveau d‘abstraction supplémentaire en empaquetant un processus, une méthodologie, une stratégie, avec ou sans accès à des données externes. De ce point de vue elles ne doivent pas être perçues comme des livrables isolés mais comme des unités portables, versionnables, lisibles par l'humain comme par l'agent, qui sont faites pour circuler, être partagées et mutualisées… et probablement un jour être cataloguées comme des ressources documentaires à part entière !
L’écosystème autour de la gestion des skills en tant qu’objet d’ingénierie se développe d'ailleurs très rapidement (SkillOpt pour le training de skills auto-apprenantes, SkillSpector pour leur audit de sécurité...) tout comme celui des plateformes collaboratives de skills et MCP, avec de nombreuses ressources partagées dans le champ du Knowledge management et de la recherche et de la publication académique : voir par exemple cette skill de cartographie des thèses basée sur l’API theses.fr, ce MCP Légifrance, les multiples MCP Arxiv comme celui-ci, cet ensemble de skills dédiées à la recherche scientifique, cette skill de revue de littérature académique...
Au dernier étage de la fusée, fabriquer ou adapter un agent consiste donc à emboîter ces différentes briques dans un système cohérent qui exploite les capacités génératives d’un modèle tout en l’encadrant par une couche de déterminisme, et dans un contexte documentaire le champ des possibles est réellement très vaste, autant en interne pour le traitement des collections (acquisitions, contrôle-qualité, gestion de plan de classement, insights de poldoc) ou autres (analyse qualitative des publications, rédaction de rapports bibliométriques) que dans l'offre de nouveaux services liés à la production de skills, le développement de MCP ou la création d’agents en soutien à sa communauté académique.
Du point de vue des bibliothécaires, l’enjeu de l’agentique est donc fondamental à maîtriser, autant en tant que nouvelles opportunités d'automatisation et de déploiement de nouveaux services à un niveau d‘abstraction plus élevé, que pour se placer en capacité d’évaluer les solutions agentiques locked-in qui vont être de plus en plus fournies par des prestataires divers et variés (quelle transparence, quel modèle hébergé à quel endroit, quel niveau de délégation du harness, est-ce que je peux répliquer localement en open la solution…?). Tout ceci est évidemment multidimensionnel, et se laisse parcourir sans surprise comme une montée en responsabilités et en compétences : depuis les exigences techniques liées à la compréhension technique des Agent harness et la capacité à déployer des solutions agentiques 100% locales (modèle et harnais) - ce que la maturité des SLM rend réaliste -, en passant par les exigences métiers de capacité à transposer de la connaissance métier en templates mobilisables par un agent IA jusqu’aux exigences de mutualisation (faire des skills produites un commun partagé dans le prolongement direct de notre culture du catalogage coopératif) et bien sûr de gouvernance.