Sans catégorie
Sujets qui n'ont pas besoin de catégorie, ou qui ne conviennent à aucune catégorie existante
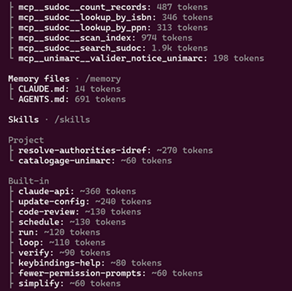
Bibliothèques et agents IA : le risque de l’invisibilisation
To be (in the IA Agent Context) or not to be






Page 1 de 3
Plus ancien »