Comment exécuter localement un LLM (2/2)?

Pour rattraper le wagon précédent...
Ollama
Ollama est un framework open source léger et extensible concu pour construire et exécuter des modèles de langage de grande taille sur son ordinateur. Sa popularité croissante (qui se mesure en partie par ses possibilités d'intégration deplus en plus nombreuses avec des outils tiers) tient à plusieurs de ses caractéristiques :
- Cross-platform : Ollama est installable très facilement sur les 3 OS Linux, MacOS et Windows, et embarque pour chacun des stratégies pré-buildées d'accélération sur GPU et CPU qui ne nécessitent aucune configuration côté utilisateur, car la couche matérielle de l'ordinateur hôte est auto-détectée. Autrement dit, une fois installé, le framework tourne en tâche de fond sans paramétrages ni blibliothèques supplémentaires.
- Bibliothèque de modèles : Ollama propose une liste bien fournie de tous les modèles compatibles installables avec pour chacun plusieurs versions et variantes disponibles et une documentation complète (licence, template de prompt, paramètres, commandes d'installation...)
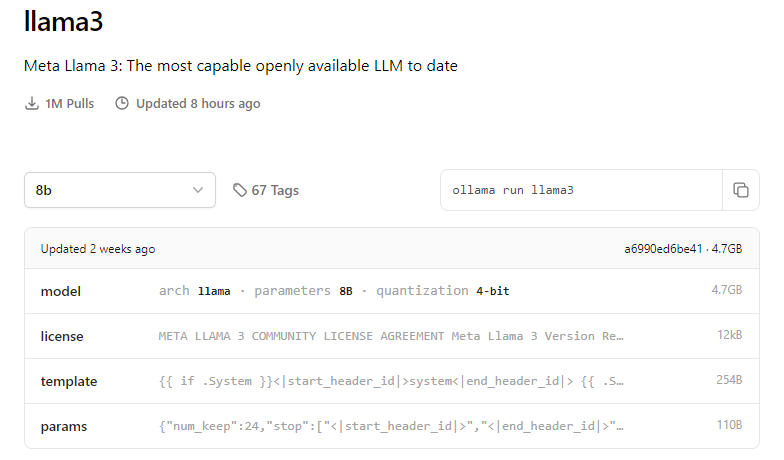
- Docker-like : en fait Ollama est basé sur la notion de Modelfiles qui, à l'image des Dockerfile, package dans un seul fichier toutes les configurations nécessaires à l'exécution d'un LLM. Donc, comme dans l'environnement Docker, il suffit d'un simple "ollama pull ..." et "ollama run..." pour télécharger et lancer un modèle.
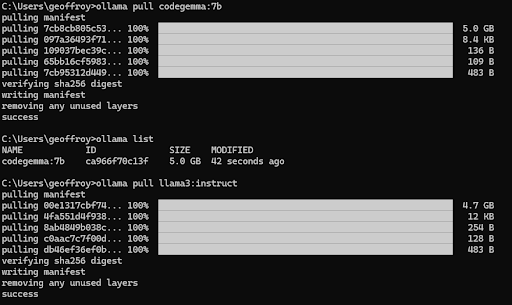
Il est aussi possible de définir des modèles customisés en configurant son propre Modelfile à partir d'un modèle existant
FROM llama3
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# sets the context window size to 4096, this controls how many tokens the LLM can use as context to generate the next token
PARAMETER num_ctx 4096
# set the system message
SYSTEM """
Answer as librarian.
"""
puis dans la console
# create the new model
ollama create librarian -f ./Modelfile
# run the model
ollama run librarian
- A noter qu'Ollama supporte aussi des modèles d'embeddings en plus des modèles de langage généralement decoder-only, rendant l'outil auto-suffisant pour un usage de type RAG par exemple.
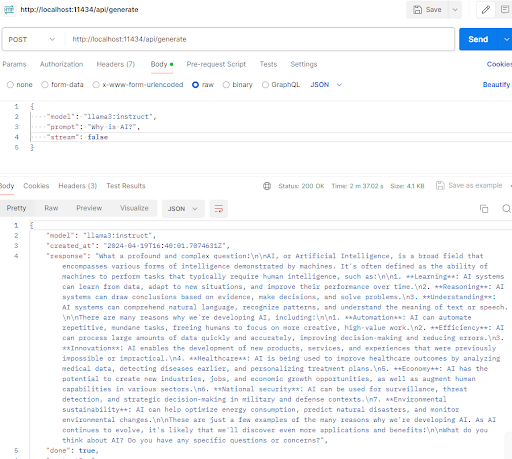
- CLI, clients Python et JS et API Rest OpenAI-like sont les trois modes d'accès aux LLMs une fois Ollama installé et au moins un modèle downloadé : concernant l'API, l'ensemble des endpoints sont documentés sur cette page et, par exemple, une requête d'inférence est aussi simple que cela
- Une image Docker officielle est également fournie si l'on souhaite conteneuriser le serveur d'API, image sur laquelle on peut bien sûr s'appuyer pour créer des containers un peu plus personnalisés
Exemple de Dockerfile
FROM ollama/ollama as ollama
ARG models
RUN ollama serve & sleep 2 && for model in $models; do ollama pull $model ; done;
EXPOSE 11434
CMD ["serve"]
puis dans la console
docker build --build-arg models="phi3:3.8b llava:7b" -t <image_name>:<tag_name> .
- Et enfin le README du dépôt Github détaille toutes les intégrations possibles avec des outils tiers
Pour résumer, Ollama est de mon point de vue (et je ne pense pas être la seule ;)) la bibliothèque la plus simple, complète et efficiente pour faire tourner des LLM en local et les intégrer dans une pile applicative en JS ou en python.
Llamafile
Llamafile est un projet ayant pour objectif de simplifier au maximum le recours aux LLMs par les utilisateurs finaux en les déclinant en fichiers uniques exécutables sur n'importe quel OS sans autre installation. Et ça marche ! Les modèles compatibles (architecture Llama seulement) sont listés dans le README sur Github et il est possible de télécharger n'importe quelle version quantizée
Exemple
# Windows
curl -L -o TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile.exe https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Linux/MacOS
curl -L -o TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
Puis pour lancer le modèle
TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile -ngl 9999
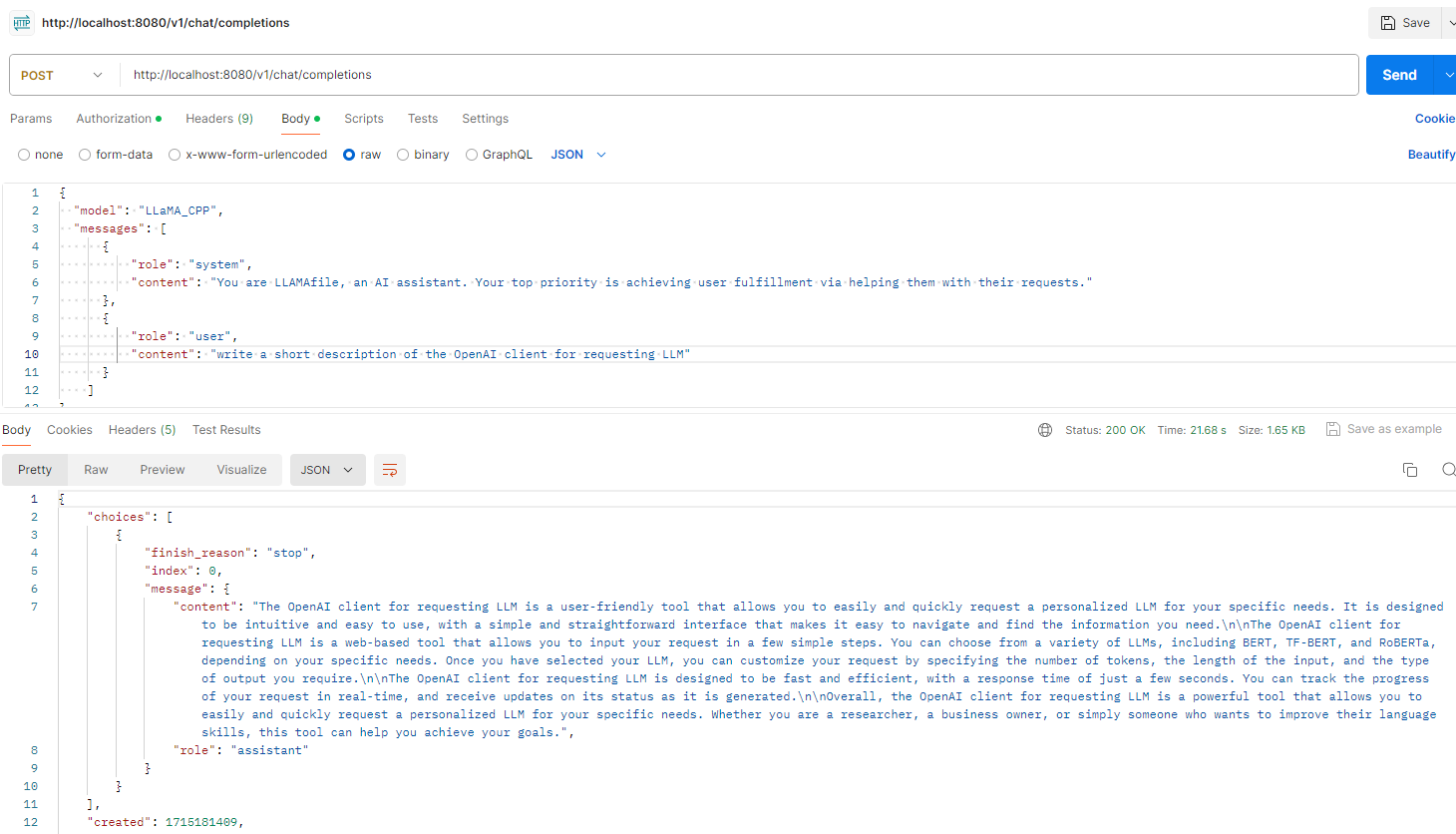
Avec l'extension .llamafile (et .llamafile.exe sous Windows), le fichier exécutable embarque non seulement le modèle mais aussi un serveur d'API OpenAi-like compatible avec le client d'API d'OpenAI (liste des endpoints ici)
Exemple de requête avec Postman
ainsi qu'une UI web miminaliste d'inférence sur le modèle accessible sur le port 8080
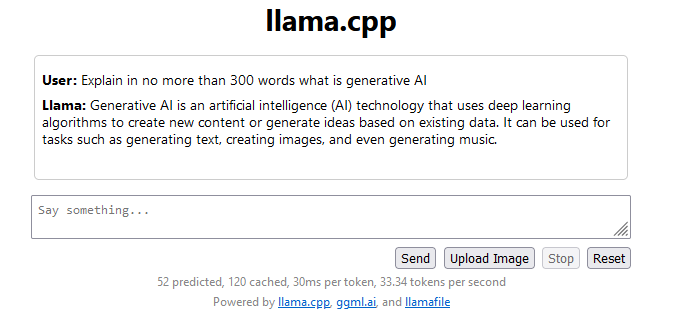
Attention, pour faire des requêtes depuis l'UI, il est nécessaire de se référer au template de prompt documenté sur HF afin de respecter la bonne syntaxe spécifique à chaque modèle.
Un point intéressant découlant de cette approche tient dans la portabilité induite du LLM : en effet, rien n'empêche de télécharger son llamafile sur une clé USB par exemple, et de l'exécuter sur n'importe quel PC au besoin !
Langchain & LlamaIndex
Et enfin, côté frameworks de développement applicatif, les deux librairies open source ayant creusé l'écart en terme d'usage sont Langchain et LlamaIndex. Mettant à disposition toutes deux des classes et fonctions composant une couche d'abstraction autour des LLMs, leur logique est toutefois sensiblement différente : Langchain, de part la variété et la flexibilité de ses composants, constitue un outil généraliste polyvalent et complet (voire - parfois inutilement- complexe) pour le chargement, le traitement et l’indexation des données, ainsi que pour l'interaction avec les LLMs, tandis que LlamaIndex, conçu pour créer des applications de recherche et de récupération, fournit des fonctionnalités plus simples et efficaces pour interroger les LLMs dans une application RAG. Au fil du temps, les deux frameworks s'enrichissent progressivement d'applications complémentaires (LangServe ou LangSmith pour Langchain, LlamaHub ou LlamaPacks pour LlamaIndex), tendant ainsi chacun à créer des écosystèmes complets pour le développement autour des LLMs.
Bonus
En guide conclusion et de synthèse sur ces divers moyens à notre disposition pour interagir avec un LLM même sur ou depuis un ordinateur grand public, voici un exemple d'application de chat LLM basique réalisée avec Streamlit, qui illustre plusieurs manières différentes de parvenir au même résultat, soit une UI de questions-réponses à un LLM de son choix fourni par une instance locale d'Ollama et/ou le cloud Nvidia et/ou Groq.

- Le code de l'application est disponible sur ce repo Github
- L'app est déployée dans un espace HuggingFace